
基于hadoop 大数据平台的非结构化地质数据集成、发现与挖掘取得突破性进展
来源:中国地调局发展中心
发布时间:2014-07-02
由中国地调局发展中心、西安中心和中国地质大学(武汉)组成的地质调查信息云平台团队经过近一年的研究和试验,在《地质调查信息网格试点建设》和《西安结点非结构化地质数据集成建设》项目研究中,对内容复杂异构、文件小碎多、数据形态碎片化、数据格式五花八门的地质非结构化数据,采用大数据技术,基于hadoop 大数据平台,基本解决了非结构化地质数据的组织、存储、快速发现和使用问题。改变了长期按目录文件存储、不利于使用的模式,将非结构化的地质数据聚集以面向数据发现和数据挖掘的“新模式”形成一个整体,构成抽象的hadoop数据挖掘和处理的“大文件”。目前已在内容复杂的非结构化数据快速组织、存储、智能化与面向数据挖掘组织、数据快速发现等方面取得重大进展,为我国智能地质调查信息快速挖掘与发现服务翻开了新的一页。
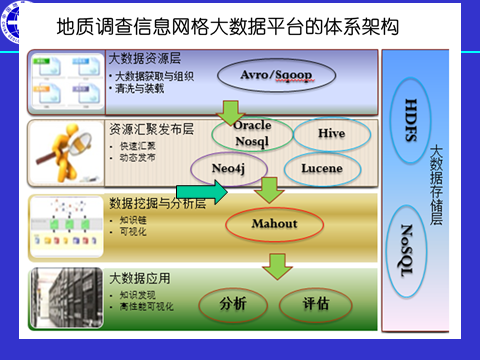
地质调查信息网格非结化大数据处理总体框架可分为四个层次(见下图),从底层到顶层依次可分为大数据资源层、汇聚层、数据挖掘与分析层及大数据应用层。在四个层次中,主要采用当前主流的多种大数据处理技术,包括Hadoop体系中的HDFS、HBase、Hive、Pig,分布式缓存技术Memcached和Redis,文本搜索框架Lucene以及机器学习与数据挖掘框架Mahout。利用上述多种技术,对地质资料成果文档等数据进行存储、组织,经过一系列的变换、分析和挖掘,从海量数据中获取有价值的信息用于地学分析和成果评估,并通过数据可视化技术来构建地质调查问题求解环境,进一步实现上层的智能化服务应用。
在示范中,用户可以看到,对一组内容复杂异构、文件小碎多、数据形态碎片化、数据格式五花八门的地质非结构化数据,通过大数据资源层、汇聚层,在ETL工具(Extract-Transform-Load 的缩写,为数据抽取、转换和加载)支持下,快速构成抽象的hadoop数据挖掘和处理的“大文件”,分布存储在不同结点,利于并行计算。同时还可通过软件快速还原文件并展示。更进一步,通过大数据平台,可以从非结构化数据快速挖掘所需的内容,如从报告寻找矿点分布的位置并快速显示在地图上。
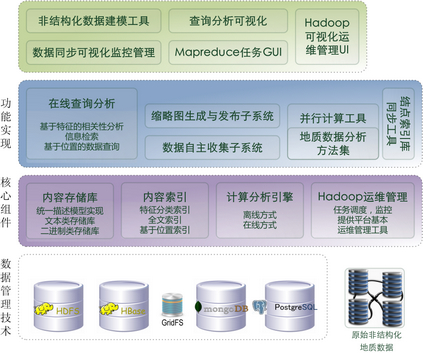
目前,非结构化地质数据管理与服务集成应用及关键技术研究平稳推进,形成了基于大数据平台的非结构化数据组织存储和发现与挖掘系统原型。完成非结构化地质数据模块前端界面设计,编写了非结构功能模块接口设计说明书,初步实现了对原始档案存入和获取,完成功能框架、用户认证模块、档案库目录管理、档案库上传管理与还原等,并根据功能需求详细制定了主要开发接口,包括档案的分页获取、档案所包含的电子文件目录、专辑所包含的电子文件目录、电子文件的下载、电子文件的删除、档案上传、档案还原、档案库可用空间、已用空间、总空间大小统计、集群整体状态、定位文件所在集群的位置接口;软件功能性框架见下图。
项目团队对地质大数据的组织和存储方法的研究成果“Organizing and Storing Method for Large-scale Unstructured Data Set with Complex Content(大规模内容复杂数据集组织与存储方法研究)” ,已被2014年8月于华盛顿举行的“COM.BigData 2014:The 1st International Summit on Big Data Computing”国际会议中录取,并列入会议讨论议题。 下半年,根据研究进展,地质调查信息云平台团队将在中国地质调查信息网格结点进行分布式和“大”数据的试验,继续重点解决内容存储库中的数据统一组织与描述模型的理论研究和验证工作,为大数据技术在智能地质调查发挥更大作用起到引领示范作用。
地质调查信息网格非结化大数据处理总体框架可分为四个层次(见下图),从底层到顶层依次可分为大数据资源层、汇聚层、数据挖掘与分析层及大数据应用层。在四个层次中,主要采用当前主流的多种大数据处理技术,包括Hadoop体系中的HDFS、HBase、Hive、Pig,分布式缓存技术Memcached和Redis,文本搜索框架Lucene以及机器学习与数据挖掘框架Mahout。利用上述多种技术,对地质资料成果文档等数据进行存储、组织,经过一系列的变换、分析和挖掘,从海量数据中获取有价值的信息用于地学分析和成果评估,并通过数据可视化技术来构建地质调查问题求解环境,进一步实现上层的智能化服务应用。
在示范中,用户可以看到,对一组内容复杂异构、文件小碎多、数据形态碎片化、数据格式五花八门的地质非结构化数据,通过大数据资源层、汇聚层,在ETL工具(Extract-Transform-Load 的缩写,为数据抽取、转换和加载)支持下,快速构成抽象的hadoop数据挖掘和处理的“大文件”,分布存储在不同结点,利于并行计算。同时还可通过软件快速还原文件并展示。更进一步,通过大数据平台,可以从非结构化数据快速挖掘所需的内容,如从报告寻找矿点分布的位置并快速显示在地图上。
目前,非结构化地质数据管理与服务集成应用及关键技术研究平稳推进,形成了基于大数据平台的非结构化数据组织存储和发现与挖掘系统原型。完成非结构化地质数据模块前端界面设计,编写了非结构功能模块接口设计说明书,初步实现了对原始档案存入和获取,完成功能框架、用户认证模块、档案库目录管理、档案库上传管理与还原等,并根据功能需求详细制定了主要开发接口,包括档案的分页获取、档案所包含的电子文件目录、专辑所包含的电子文件目录、电子文件的下载、电子文件的删除、档案上传、档案还原、档案库可用空间、已用空间、总空间大小统计、集群整体状态、定位文件所在集群的位置接口;软件功能性框架见下图。

 京公网安备 11010202007433号
京公网安备 11010202007433号